谷歌發布 TranslateGemma:基於 Gemma 3 架構的最強開放翻譯模型,手機端也能流暢運行
谷歌正式發布基於 Gemma 3 架構的 TranslateGemma 翻譯模型系列,提供 4B、12B 和 27B 三種規格,支持 55 種核心語言。該模型利用獨特的兩階段微調工藝,在翻譯質量上超越同級競品,並完整保留了強大的多模態能力。本文將深入解析其技術架構、性能表現及在邊緣計算領域的應用前景。
隨著全球化交流的日益頻繁,跨語言溝通的需求呈現爆發式增長。儘管現有的翻譯工具已經相當成熟,但在處理低資源語言、保持上下文語境以及在邊緣設備上運行高性能模型方面,仍面臨諸多挑戰。
2026 年 1 月 15 日,谷歌(Google)再次投下一枚重磅炸彈,正式發布了基於其最新 Gemma 3 架構的開放翻譯模型系列——TranslateGemma。這一系列模型的問世,不僅標誌著谷歌在機器翻譯領域的又一次技術飛躍,更為開發者和研究人員提供了前所未有的強大工具。TranslateGemma 推出了 4B、12B 和 27B 三種參數規模,全面覆蓋了從移動端設備到高性能雲端服務器的各類應用場景,並首發支持 55 種核心語言及多模態圖像翻譯功能。目前,該模型已在 Kaggle、Hugging Face 及 Vertex AI 全面上線,供全球開發者免費下載和使用。
關鍵摘要 (Key Takeaways)
- 多樣化模型尺寸:提供 4B(移動端)、12B(消費級 PC)和 27B(雲端 TPU/GPU)三種規格,精準匹配不同算力需求。
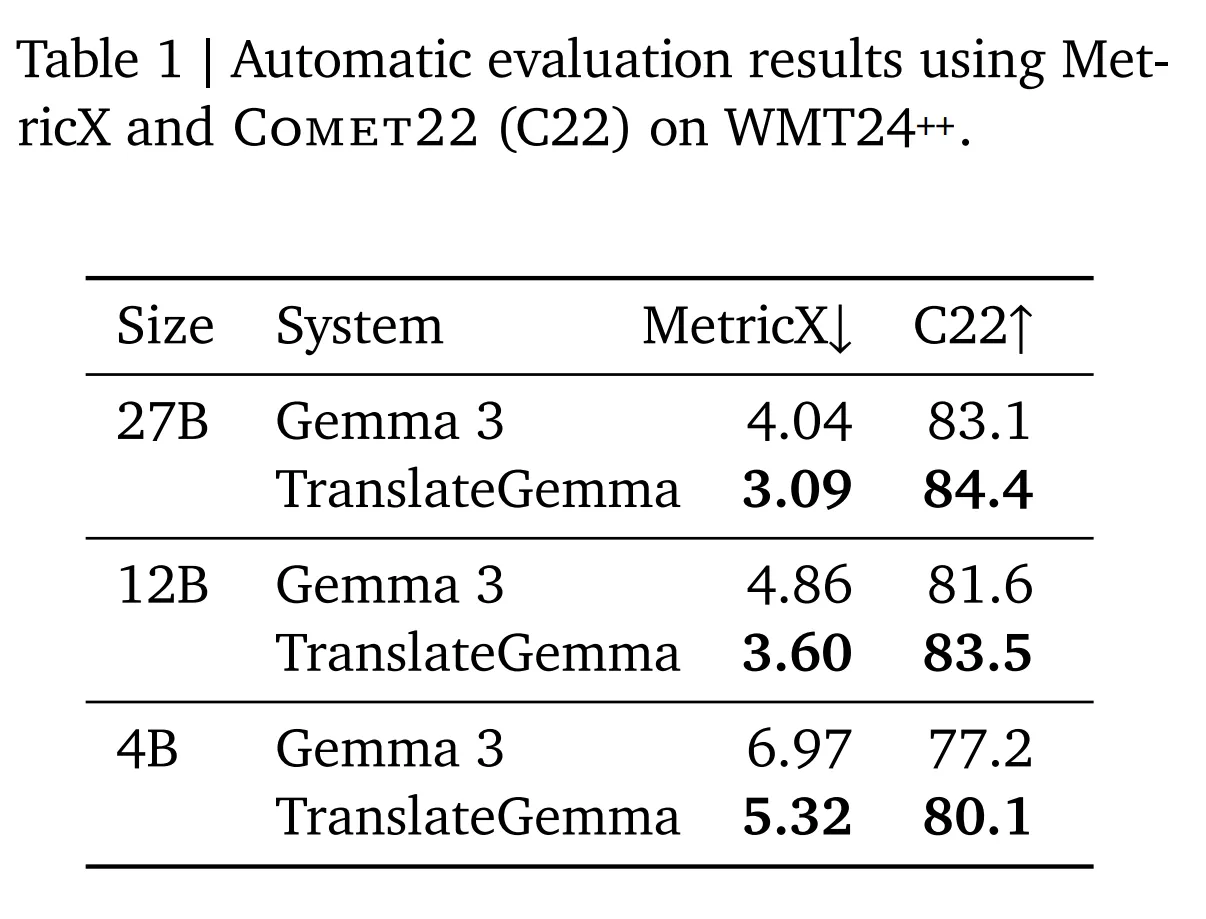
- 卓越的性能表現:12B 版本翻譯質量超越 27B 基線模型,實現「減半算力,倍增效能」。
- 獨創微調工藝:採用「監督微調(SFT)+ 強化學習(RL)」的兩階段訓練策略,引入 MetricX-QE 和 AutoMQM 獎勵模型。
- 原生多模態能力:完整繼承 Gemma 3 的多模態特性,無需額外訓練即可實現圖像內文字的高質量翻譯。
- 廣泛語言覆蓋:首發支持 55 種核心語言,並已開展對近 500 鐘語言的探索性訓練,致力於保護瀕危語言。
1. 技術架構:Gemma 3 的強大基因與創新微調
TranslateGemma 的核心優勢在於其強大的基礎架構——Gemma 3。作為谷歌開放模型家族的最新成員,Gemma 3 本身就具備了極高的語言理解和生成能力。然而,通用的語言模型在處理專業翻譯任務時,往往會出現「幻覺」或語體風格不一致的問題。為了克服這些障礙,谷歌團隊為 TranslateGemma 量身打造了一套獨特的訓練方案。
1.1 兩階段微調工藝 (Two-Stage Fine-Tuning)
TranslateGemma 的高密度智能源於其精心設計的「兩階段微調」工藝,這一過程將高質量的數據輸入與先進的強化學習算法完美結合:
-
監督微調 (SFT) 階段: 在這一階段,谷歌利用其最強大的 Gemini 模型生成了海量的高質量合成數據,並將其與經過嚴格篩選的人工翻譯數據進行混合。這種「人機協作」的數據準備方式,既保證了翻譯的準確性,又極大豐富了語料庫的多樣性。通過對 Gemma 3 底座進行 SFT 訓練,模型初步掌握了各語種間的轉換規律和語言特徵。
-
強化學習 (RL) 階段: 為了讓譯文更加自然、流暢且符合目標語言的文化語境,谷歌引入了強化學習機制。這一階段的關鍵在於使用了 MetricX-QE 和 AutoMQM 等先進的獎勵模型(Reward Models)。
- MetricX-QE:這是一種無參考(Reference-free)的質量評估指標,能夠直接預測譯文的質量分數,幫助模型判斷「好」與「壞」。
- AutoMQM:這是一種自動化的多維質量指標(Multidimensional Quality Metrics),能夠從語法、流暢度、準確性等多個維度對譯文進行細粒度打分。
通過這些獎勵模型的引導,TranslateGemma 學會了自我修正,生成出更符合人類閱讀習慣的譯文,而非機械式的逐詞對譯。
2. 性能與效率:重新定義「小模型」的極限
在 AI 領域,長期以來存在著「參數即正義」的觀點,認為模型越大效果越好。然而,TranslateGemma 打破了這一刻板印象,展示了通過精細優化,小模型也能展現出驚人的實力。
2.1 12B 模型:各項指標的「甜蜜點」
根據谷歌團隊利用 WMT24++ 基準(包含高、中、低資源語言的 55 鐘語言)進行的嚴格測試,TranslateGemma 12B 版本的表現尤為搶眼。測試結果顯示,其翻譯質量竟然超越了參數與其兩倍之大的 Gemma 3 27B 基線模型。
這意味著什麼?對於開發者而言,這代表著極致的性價比。使用 12B 模型,開發者僅需消耗一半的顯存和算力資源,即可獲得比以往大模型更保真、更準確的翻譯結果。這直接帶來了吞吐量的大幅提升和延遲的顯著降低,使得在本地消費級筆記本電腦(如配備 RTX 40 系顯卡的筆記本)上運行研究級的翻譯服務成為可能。
2.2 4B 模型:移動端 AI 的新標竿
對於資源受限的移動端和邊緣設備,TranslateGemma 4B 模型提供了一個完美的解決方案。儘管體積小巧,但它並未在性能上妥協。測試表明,其翻譯能力與 12B 的基線模型相當。這意味著,未來的智能手機、翻譯筆甚至智能眼鏡,都可以在不聯網的情況下,實現高質量的實時互譯,這對於出境旅遊、商務會議等場景具有革命性的意義。
3. 多模態與語言多樣性:跨越邊界的溝通
TranslateGemma 不僅僅是一個文本翻譯工具,它還繼承了 Gemma 3 的**多模態(Multimodal)**基因,並對語言多樣性給予了前所未有的關注。
3.1 圖像翻譯的無縫融合
傳統的圖像翻譯通常需要 OCR(光學字符識別)和 MT(機器翻譯)兩個獨立步驟,容易造成誤差累積。而得益於 Gemma 3 的原生多模態架構,TranslateGemma 能夠直接理解圖像內容。
谷歌的測試表明,無需額外針對視覺任務進行微調,TranslateGemma 在文本翻譯上的能力提升,直接增強了其處理圖像內文字的效果。它能夠更準確地識別複雜背景下的文字,並結合圖像的視覺語境(如路牌、菜單、海報)給出恰當的翻譯。例如,在翻譯一張帶有雙關語廣告牌的照片時,模型會參考畫面內容,給出更具神韻的譯文。
3.2 守護瀕危語言
在語言覆蓋方面,TranslateGemma 採取了「核心+探索」的策略:
- 核心語言:重點優化並驗證了 55 種全球核心語言,涵蓋了西班牙語、中文、印地語、阿拉伯語等,確保了對全球絕大多數人口的服務能力。
- 長尾語言探索:谷歌進一步探索訓練了近 500 種語言。這項工作對於學術界研究和保護瀕危語言具有重要價值。通過將高資源語言的知識遷移到低資源語言,TranslateGemma 為那些面臨消失風險的語言建立了數字檔案,讓它們在 AI 時代得以延續。
4. 部署場景與應用建議
為了適應不同的開發需求,谷歌對 TranslateGemma 的三種尺寸進行了精準的場景定位,開發者應根據實際需求選擇合適的模型:
-
4B 模型(端側首選):
- 目標設備:旗艦級智能手機、樹莓派等邊緣計算設備、離線翻譯機。
- 優勢:極低延遲、隱私安全(數據不出本地)、低功耗。
- 適用場景:實時語音翻譯 App、旅行助手、智能家居指令解析。
-
12B 模型(開發者利器):
- 目標設備:消費級筆記本電腦(配備 16GB+ 顯存)、工作站。
- 優勢:平衡了性能與資源消耗,具備研究級的翻譯質量。
- 適用場景:本地文檔翻譯工具、字幕組輔助翻譯、學術研究對照。
-
27B 模型(極致追求):
- 目標設備:單張 H100 GPU、雲端 TPU 集群、企業級服務器。
- 優勢:提供最頂級的翻譯質量和細微語境捕捉能力。
- 適用場景:專業文學翻譯、法律/醫療文殊翻譯、大型跨國企業的實時會議系統。
總結與展望
TranslateGemma 的發布,再次證明了開源社區與科技巨頭協同創新的力量。通過將 Gemma 3 的先進架構與創新的 RLHF(基於人類反饋的強化學習)技術相結合,谷歌不僅提升了機器翻譯的基準線,更重要的是,它降低了高質量翻譯技術的門檻。
從手機端的 4B 模型到雲端的 27B 巨獸,TranslateGemma 構建了一個全方位的語言服務生態。它讓「巴別塔」的重建不再僅僅依賴於昂貴的雲服務,而是可以運行在每個人的口袋裡、桌面上。隨著開發者社區的加入,我們有理由相信,基於 TranslateGemma 的創新型應用將會井噴式湧現,進一步消除人類語言的隔閡。
免責聲明:本文基於 2026 年 1 月 16 日的公開信息撰寫。模型性能和具體參數可能隨版本更新而有所變化,請以谷歌官方技術文檔和 Hugging Face 頁面為準。